..
Git Re-Basin: Merging Models modulo Permutation Symmetries
Arxiv: https://arxiv.org/pdf/2209.04836.pdf
Highlights
- They propose 3 new methods to align the weights of 2 trained models through finding a suitable permutation between the elements of their hidden layers.
- They show that Linear Mode Connectivity, i.e loss landscape of interpolated models of 2 separately trained models is almost flat, is a byproduct of SGD.
- Most notably, they propse a method that allows the combination of two independently trained models that achieves better performance than the inital models.
Methods

The authors propose three methods to perform model weight permutations:
- Activation Matching: solving a linear assignment problem between layer activations.
- Weight Matching (Best tradeoff): Solve LAP per layer iteratively until convergence.
- Staright Through estimator: “learn” the best permutation using gradient descent.
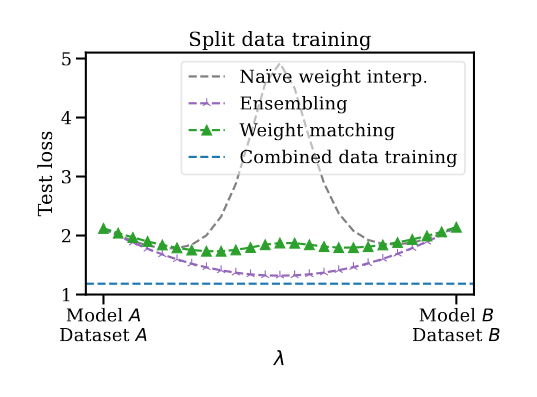
The result of the permutation symmetries that can be exhibited by SGD trained models is that we can train models on separate datasets and then combine them in a way that outperforms ensembling (i.e less params needed) and naive interpolation.